OpenClaw 批量解析带有人工字迹的 PDF 文件
目前 OpenClaw 使用的模型大都为 LLM 大语言模型,无法解析一些 png、ppt 类型的文档,需要用外部的工具或者使用其他的 Skill 去解析 PDF
解决方案:
使用minerU 的skill 地址:https://github.com/Nebutra/MinerU-Skill
token 获取地址:https://mineru.net/apiManage/docs
pdf 内容如下:

接入后处理效果如下:
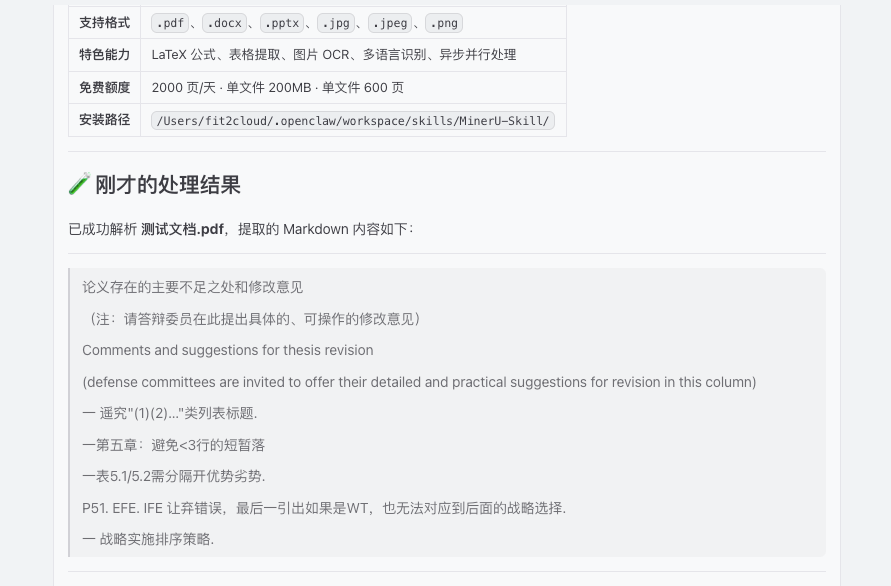
注意⚠️:因为示例文件字迹太过潦草,识别的内容可能有出入,正常字迹好点的识别率可以到98%。
本章使用的 skill 是用公网的 minerU 的模型,若数据敏感则可以考虑使用本地部署的 minerU 进行解析;