混元 HY-MT2 翻译模型
5月22号,腾子发布并开源了一款专注于支持 33 种语言之间互译的翻译模型。其中,HY-MT2-7B 是在 WMT25 夺冠模型HY-MT-7B 基础上的升级版本,针对解释性翻译和混合语言场景进行了优化,新增了术语干预、上下文翻译和格式化翻译功能。Hy-MT2 在通用翻译、实际业务、专业领域及指令对齐等多类翻译任务中综合实力优异。7B 与 30B-A3B 模型开启快思模式后,性能领先 DeepSeek-V4-Pro、Kimi K2.6 等开源模型;轻量化 1.8B 版本整体表现,同样优于微软、豆包等主流商用翻译接口。
以下是发布的论文魔塔社区的速读内容:
魔塔论文地址:https://www.modelscope.cn/papers/2605.22064/aiRead
全文摘要
Hy-MT2多语言翻译模型,该模型包括三个不同大小的版本:1.8B、7B和30B-A3B(混合专家),支持33种语言之间的翻译,并且能够有效地遵循多种语言的翻译指令。通过使用AngelSlim 1.25位极端量化技术,将1.8B模型压缩到仅需要440MB的存储空间,同时提高了推理速度。在多个维度上的评估表明,Hy-MT2在通用、商业场景、特定领域以及遵循翻译指令的任务中都表现出色。此外,该模型还增强了对专业领域的适应能力,例如金融、法律和医学等领域,同时也强化了对实际业务场景的适应能力,如网页、会议和社交内容等。总体而言,Hy-MT2系统地解决了先前模型在特定领域翻译、实际业务场景翻译、遵循翻译指令、与最强闭源模型相比性能差距以及高效设备部署等方面的局限性,为现实世界的应用提供了高质量、高效的多能力多语言翻译模型。
我这里用办公室的双卡L20进行测试模型;
模型下载
modelscope download --model Tencent-Hunyuan/Hy-MT2-7B-FP8 --local_dir /data/Hy-MT2-7B-FP8docker-compose.yml
services:
Hy-MT2-7B-FP8:
container_name: Hy-MT2-7B-FP8
image: vllm/vllm-openai:v0.20-cu130
privileged: true
restart: always
ports:
- "8000:8000"
command: [
"/data/Hy-MT2-7B-FP8",
"--served-model-name", "Hy-MT2-7B-FP8",
"--quantization", "compressed-tensors",
"--kv-cache-dtype", "fp8_e4m3",
"--max-model-len", "4096",
"--max-num-seqs", "30",
"--gpu-memory-utilization", "0.7",
"--enable-prefix-caching",
"--enable-chunked-prefill",
"--async-scheduling",
"--host", "0.0.0.0",
"--tensor-parallel-size", "2",
"--generation-config", "vllm",
]
volumes:
- /data/Hy-MT2-7B-FP8:/data/Hy-MT2-7B-FP8
environment:
- TZ=Asia/Shanghai
- CUDA_VISIBLE_DEVICES=0,1
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["0"]
capabilities: [gpu]
压测2k上下文的结果如下:
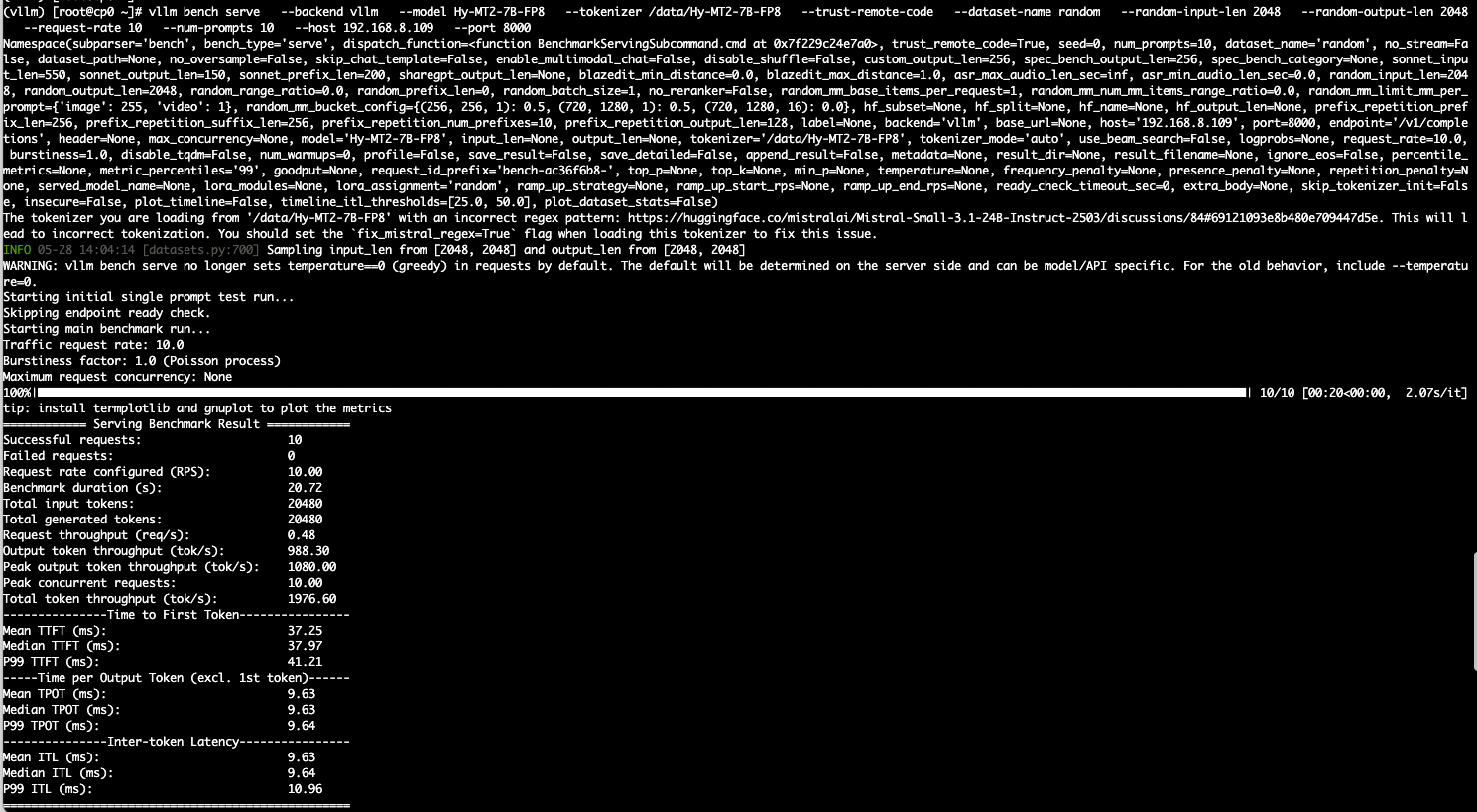
压测结果显示,平均每秒197个token,nvidia-smi结果显存占用64G