MaxKB 使用全量检索为空的问题
现象
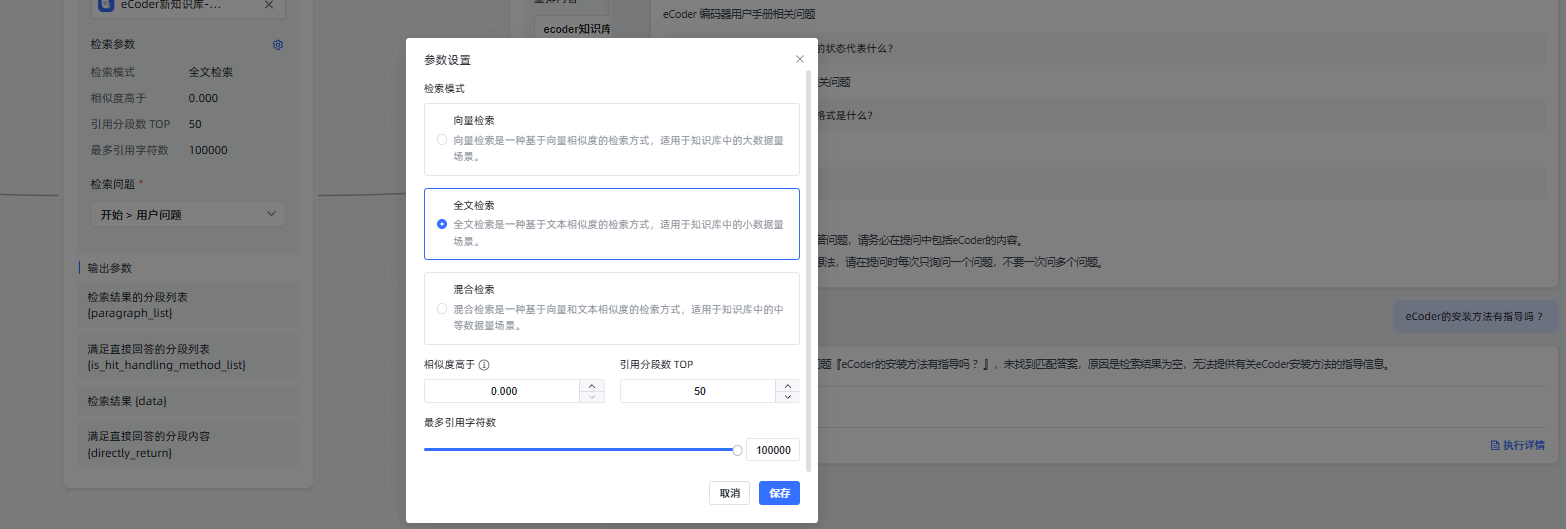
客户使用向量检索是有分段返回的,但是使用全量检索发现检索为空,但是知识库中是存在这个问题的相关分段的。

排查过程
通过查看代码,得知 MaxKB 的全文检索为关键词检索
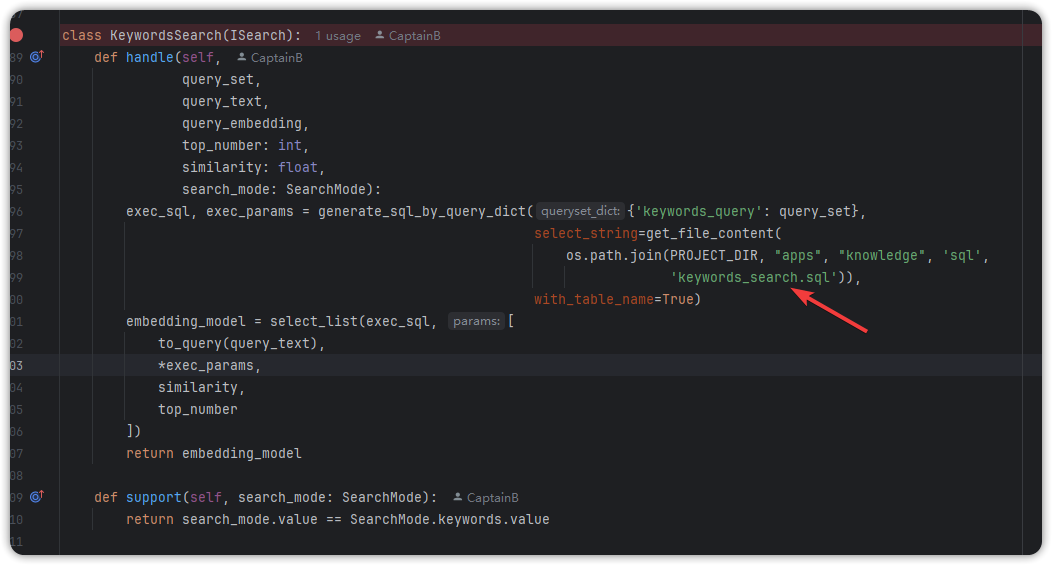
keywords_search.sql 模板 SQL 如下:
SELECT
paragraph_id,
comprehensive_score,
comprehensive_score as similarity
FROM
(
SELECT DISTINCT ON
("paragraph_id") ( similarity ),* ,similarity AS comprehensive_score
FROM
( SELECT *,ts_rank_cd(embedding.search_vector,websearch_to_tsquery('simple',%s),32) AS similarity FROM embedding ${keywords_query}) TEMP
ORDER BY
paragraph_id,
similarity DESC
) DISTINCT_TEMP
WHERE comprehensive_score>%s
ORDER BY comprehensive_score DESC
LIMIT %s得到模板 SQL 就需要找到 实际上完整的 SQL 进行对比;
修改 MaxKB 的 pgsql 配置文件,开启 debug 模式,查看执行的真实 SQL ;
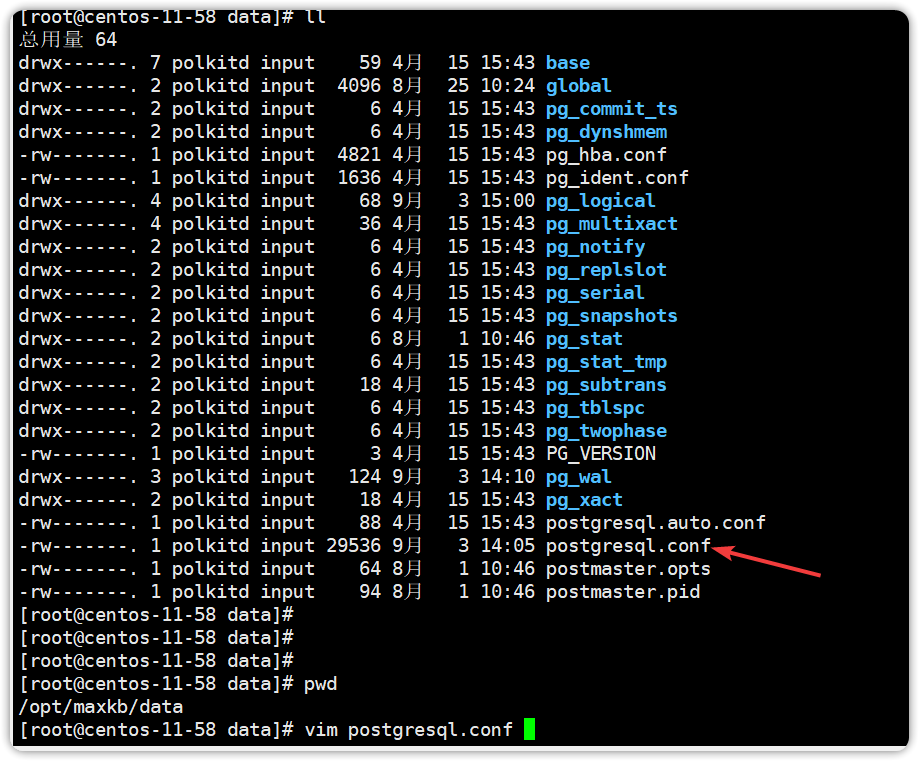
添加以下参数后,重启一下 pgsql ;
log_min_duration_statement = 0 # 记录所有执行时间的SQL
log_line_prefix = '%t [%p] [%u@%d] ' # 日志格式,包含时间、用户、数据库然后本地进行调试全文检索获取真实的 SQL 语句;
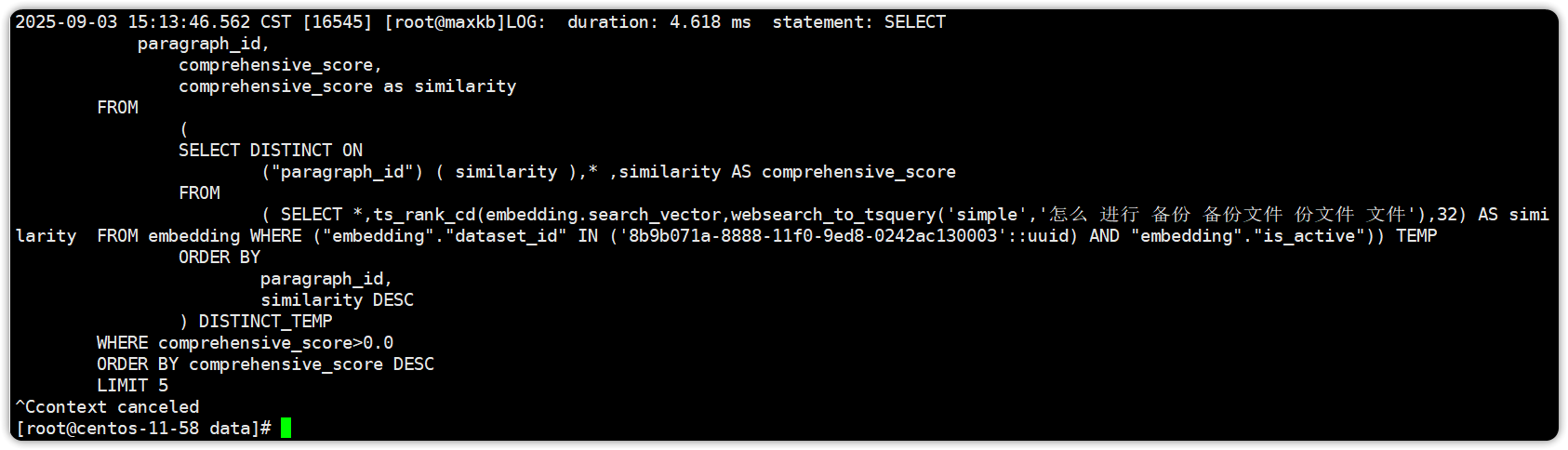
使用全文检索分别输入【备份文件】和【怎么进行备份文件】获得他们两个完整 SQL 进行对比;
SELECT
paragraph_id,comprehensive_score,comprehensive_score as similarity
FROM
(
SELECT DISTINCT ON
("paragraph_id") ( similarity ),* ,similarity AS comprehensive_score
FROM
( SELECT *,ts_rank_cd(embedding.search_vector,websearch_to_tsquery('simple','备份 备份文件 份文件 文件'),32) AS similarity FROM embedding WHERE ("embedding"."dataset_id" IN ('8b9b071a-8888-11f0-9ed8-0242ac130003'::uuid) AND "embedding"."is_active")) TEMP
ORDER BY
paragraph_id,similarity DESC
) DISTINCT_TEMP
WHERE comprehensive_score>0.0
ORDER BY comprehensive_score DESC
LIMIT 5SELECT
paragraph_id,comprehensive_score,comprehensive_score as similarity
FROM
(
SELECT DISTINCT ON
("paragraph_id") ( similarity ),* ,similarity AS comprehensive_score
FROM
( SELECT *,ts_rank_cd(embedding.search_vector,websearch_to_tsquery('simple','怎么 进行 备份 备份文件 份文件 文件'),32) AS similarity FROM embedding WHERE ("embedding"."dataset_id" IN ('8b9b071a-8888-11f0-9ed8-0242ac130003'::uuid) AND "embedding"."is_active")) TEMP
ORDER BY
paragraph_id,similarity DESC
) DISTINCT_TEMP
WHERE comprehensive_score>0.0
ORDER BY comprehensive_score DESC
LIMIT 5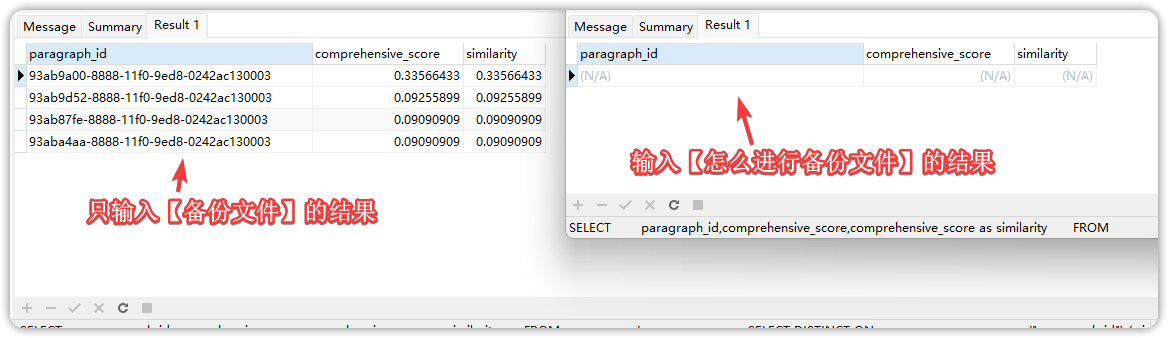
提出疑问为什么关键词多了"怎么" ,"进行" 这两个关键词就会导致全文检索无法检索到信息了呢?
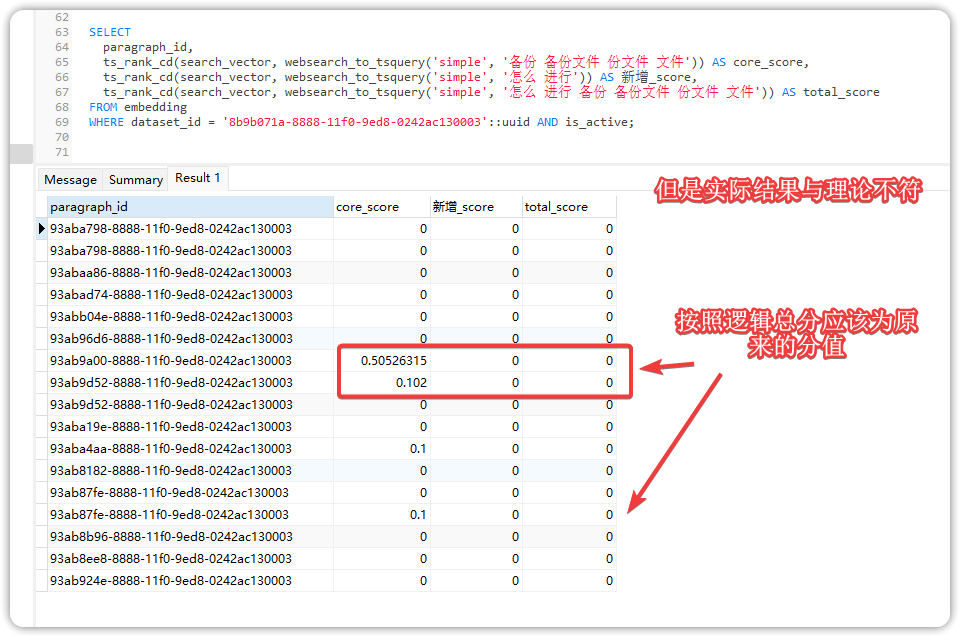
通过测试核心词和新增词的匹配分数前后对比 SQL 发现:
按照 ts_rank_cd 的打分逻辑
1.关键词在文本出现次数越多,分数越高;
2.关键词出现文本靠前位置(如开头),分数越高;
3.多个关键词匹配的时候,分数是叠加关系,但存在权重稀释效应即关键词越多,单个词的贡献占比可能降低;
打个比方,如果文本中仅包含 “备份”和“文件”,当查询关键词为['备份', '文件']时,分数由这两个词的匹配度叠加而成;若新增['怎么', '进行']且文本中不含这两个词,这两个词的贡献为 0,但原有词的分数仍存在,总分数为原有分数(不会因新增 0 权重词而变为 0)。
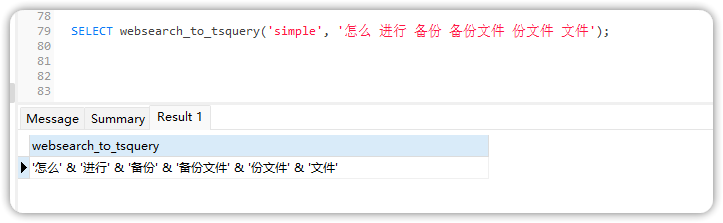
通过进一步的排查发现 websearch_to_tsquery 函数对多关键词的解析结果为 ”and“ 逻辑,而不是 ”or“ 逻辑;
这样就会导致关键词越多,如果当中有关键词它的分值为0,就会导致这次全文检索,检索不到分段内容;
初步改进思路:
可以将 websearch_to_tsquery 函数换成 to_tsquery 并手动添加 "| "条件,如下:
SELECT
paragraph_id,comprehensive_score,comprehensive_score as similarity
FROM
(
SELECT DISTINCT ON
("paragraph_id") ( similarity ),* ,similarity AS comprehensive_score
FROM
( SELECT *,ts_rank_cd(embedding.search_vector,to_tsquery('simple', '怎么 | 进行 | 备份 | 备份文件 | 份文件 | 文件'),32) AS similarity FROM embedding WHERE ("embedding"."dataset_id" IN ('8b9b071a-8888-11f0-9ed8-0242ac130003'::uuid) AND "embedding"."is_active")) TEMP
ORDER BY
paragraph_id,similarity DESC
) DISTINCT_TEMP
WHERE comprehensive_score>0.0
ORDER BY comprehensive_score DESC
LIMIT 5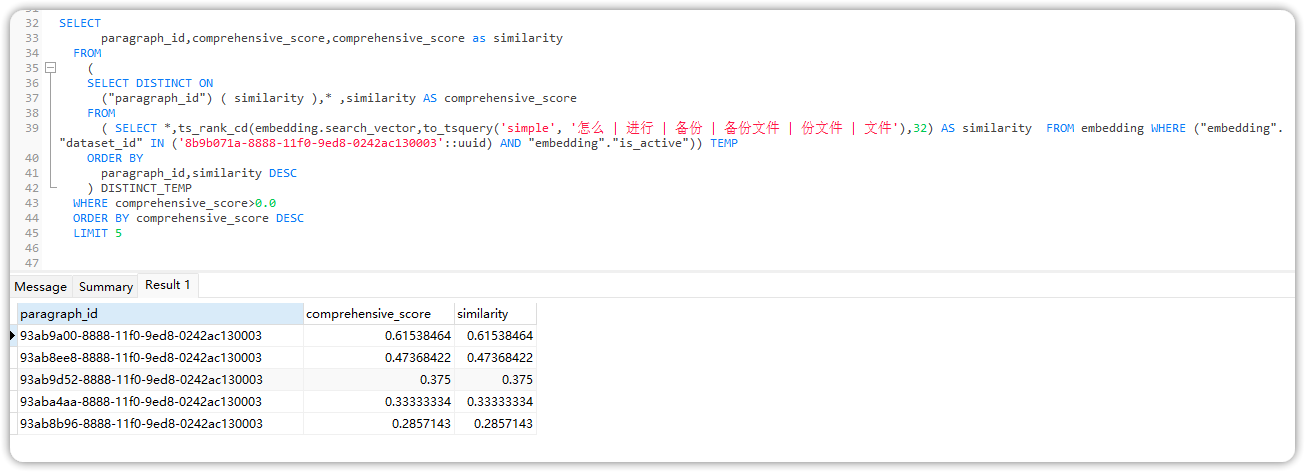
总结
全文检索不适合用户问题,因为用户问题一般为一个完整的句子,一个完整的句子会被切分出一个或者多个分值为 0 的关键词,导致全文检索为空的情况;
目前只能建议客户使用向量检索或者混合检索。