MaxKB 的 RAG 检索机制
chunks
概念
Chunks 指的是把原始文档拆分成的一段段小文本片段(段落、句子、固定 token 段等),每个 chunk 作为一个向量的基础单元,用于向量化和检索。
必要性
向量模型输入长度有限(如最多 512 或 8192 tokens)
太长的文本嵌入效果反而下降(信息稀释)
RAG 检索必须以“块”为单位来找相关内容
策略
目前支持很多很多的分段策略.以下是常见的。
以 langchain 为例:
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 目前 langchain 提供了很多种文档切分方式
# 为了避免切分的时候导致上下文丢失。固定500token,且上下100token重叠 也叫 滑动窗口
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
chunks = splitter.split_text(document_text)需要注意的是chunks的长度一定不能超过Text Embedding Model的Token限制,否则会报错。MaxKB的分段内容不是最终的chunks,因为Text Embedding Model都有输入Token的限制。但是MaxKB的分段内容确实是为了给LLM进行使用的。所以如果有用户问我们为什么没有dify的父子分段时?其实我们的分段就是父子分段。具体查看后续的 MaxKB 源码剖析向量化过程会详细讲解。
Vector Search (向量检索)
常见的相似度/距离度量的方法
余弦相似度:两个向量夹角越小 → 相似度越高 → 越“像”
欧氏距离:两个向量点靠得越近 → 越相似
曼哈顿距离:像“走街道”一样的距离,而非“穿墙直线”
向量模型如 BGE, Qwen-Embedding, OpenAI Embedding,在训练时就优化了余弦相似度,所以使用 Cosine Similarity 是最正确的选择。
以 PostgreSQL 下安装了 vector 插件为例实现检索的方式见下:
-- embedding 是向量字段
-- 余弦相似度(需要向量归一化)
SELECT id, content
FROM documents
ORDER BY embedding <#> '[0.1, 0.2, ...]' -- <#> 是 cosine distance
LIMIT 5;
-- 欧氏距离
SELECT * FROM documents
ORDER BY embedding <-> '[0.1, 0.2, ...]'
LIMIT 5;Full-text Retrieval (全文检索)
不使用向量或语义嵌入,只靠词出现的位置与频率判断“是否相关”。
实现方式:
构建倒排索引(Inverted Index)
用户问题按关键词分词
在全文索引中查找包含这些词的文本
使用 BM25 / TF-IDF 排序
优点:
✅ 支持精确关键词查找(如代码、法律条款)
✅ 快速、成熟、稳定
✅ 能解释为什么匹配(可视化词命中)
缺点:
❌ 不理解语义(“合同” ≠ “协议”)
❌ 不支持自然语言改写
❌ 不支持模糊表达、口语问题
Hybrid Retrieval(混合检索)
结合向量检索与关键词检索,互补长短板,提升召回质量与准确率。
具体实现类型:
并行检索 + 合并(Parallel Retrieval + Merge)
同时对查询进行:
向量检索(语义)
全文/BM25检索(关键词)
合并两个结果集
可选:根据相似度或打分进行排序
MaxKB混合检索默认的实现这种
两阶段检索(Two-stage / Rerank-based Retrieval)
关键词召回 → 向量 rerank
向量召回 → reranker 模型精排
特征融合(Score Fusion / Feature Combination)
对每个文档分别计算:
向量相似度得分(如 cosine)
BM25 或 TF-IDF 得分
按一定公式加权组合为一个总分
排序返回
Dify/FastGPT 常用的模式。但是MaxKB在工作流里面也可以做到如全文检索0.33+向量检索0.75 然后重排
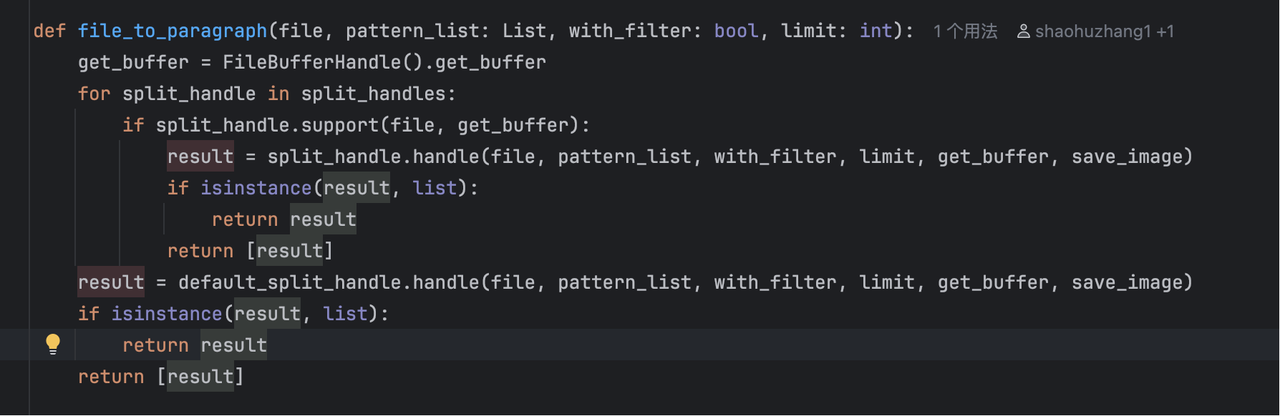
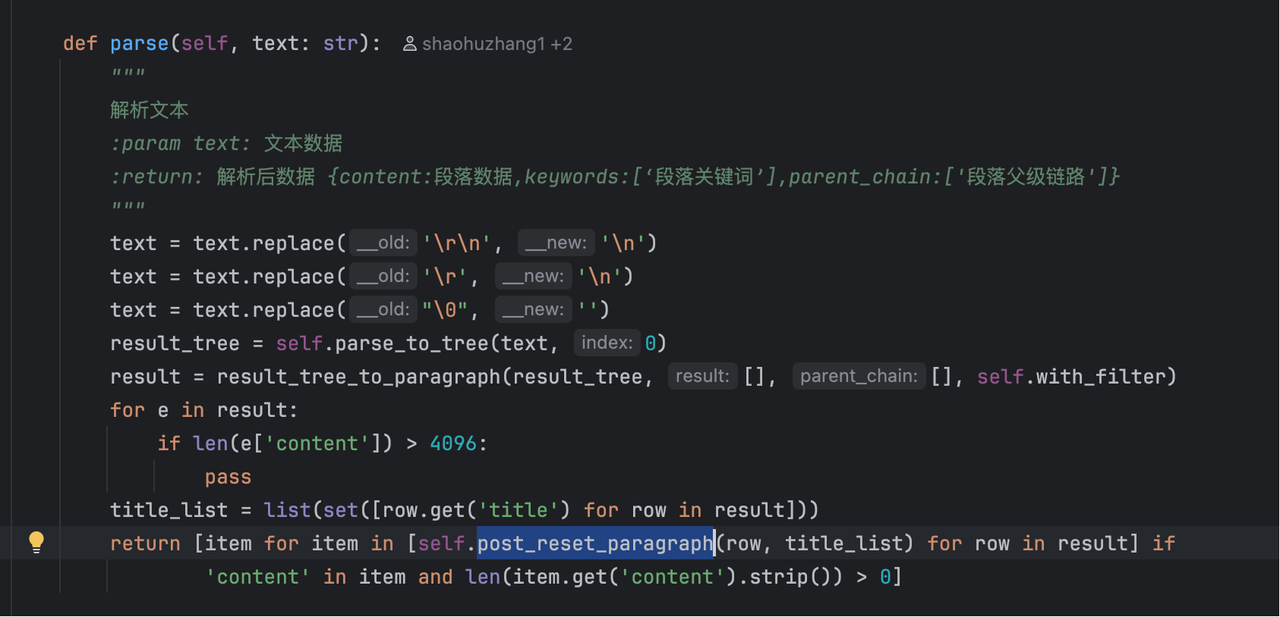
MaxKB 分段机制
分段处理
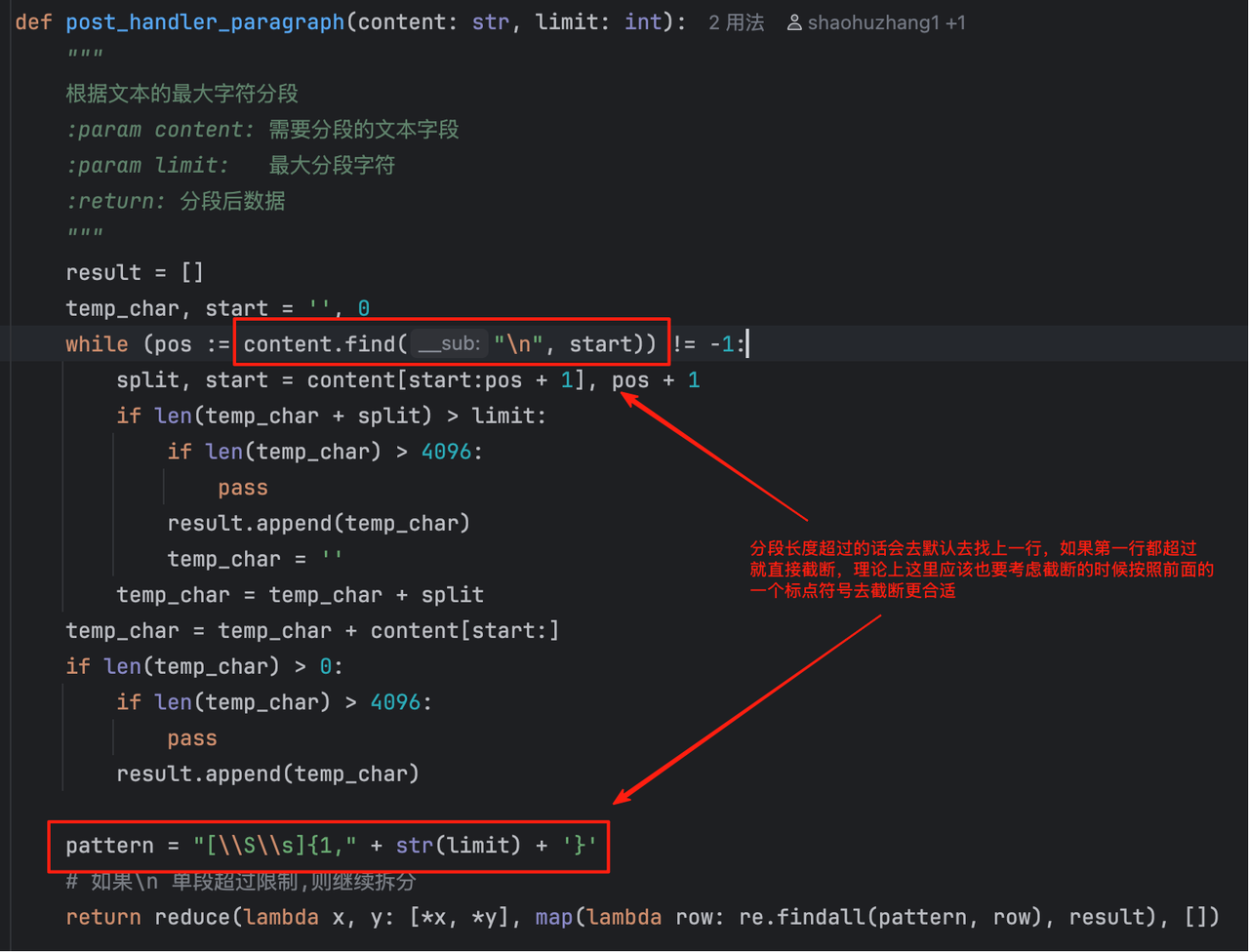
将文本分割成段落,如果超过限定长度就会往前的一个换行符进行截断,这个地方其实有点问题,应该扫描标点符号进行截断会比较合适。所以我们的在分段的时候切记一定要保持完整的段落不然后面向量化也会出现缺失上下文的问题。
向量化与分词
向量化和分词都是异步任务进行处理的。向量化和分词都会讲已经做好的分段进行两次切分成长度小于256个字符的完整一句话的句子的chunk。其实从这里我们就可以理解MaxKB的向量召回就是父子分段的方式进行召回。表结构:
数据表 "public.embedding"
栏位 | 类型 | 校对规则 | 可空的 | 预设
---------------+------------------------+----------+----------+------
id | character varying(128) | | not null |
source_id | character varying(128) | | not null |
source_type | character varying(5) | | not null |
is_active | boolean | | not null |
embedding | vector | | not null | 向量
meta | jsonb | | not null | 元数据
dataset_id | uuid | | not null | 知识库ID
document_id | uuid | | not null | 文档ID
paragraph_id | uuid | | not null | 分段ID
search_vector | tsvector | | not null | 分词结果向量化 embedding
默认我们在向量化之前还会对已经做了分段内容进行再次切分,切分规则为判断字符小于256长度的前面一句完整的句子。分段具体内容包含(标题+"\n" + 内容)。这里需要注意的是关联的问题不会进行二次切分会作为一个整体给到文本嵌入模型进行向量化。具体参考见下
SELECT
problem_paragraph_mapping."id" AS "source_id",
paragraph.document_id AS document_id,
paragraph."id" AS paragraph_id,
problem.dataset_id AS dataset_id,
0 AS source_type,
problem."content" AS "text",
paragraph.is_active AS is_active
FROM
problem problem
LEFT JOIN problem_paragraph_mapping problem_paragraph_mapping ON problem_paragraph_mapping.problem_id=problem."id"
LEFT JOIN paragraph paragraph ON paragraph."id" = problem_paragraph_mapping.paragraph_id
${problem}
UNION
SELECT
paragraph."id" AS "source_id",
paragraph.document_id AS document_id,
paragraph."id" AS paragraph_id,
paragraph.dataset_id AS dataset_id,
1 AS source_type,
concat_ws(E'\n',paragraph.title,paragraph."content") AS "text",
paragraph.is_active AS is_active
FROM
paragraph paragraph
${paragraph}