Qwen3.6-27B 模型效果实测
模型部署
模型下载
用魔塔命令下载模型文件,Qwen/Qwen3.6-27B
modelscope download --model Qwen/Qwen3.6-27B --local_dir /data/Qwen3.6-27Bdocker-compose.yml 文件
我这里是 L20 两张卡一共 92G 显存
services:
qwen35:
container_name: Qwen3.6-27B
image: vllm/vllm-openai:v0.20-cu130
restart: always
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
ipc: host
shm_size: 64gb
ports:
- "8000:8000"
volumes:
- /data/Qwen3.6-27B/:/models/Qwen3.6-27B
command: >
/models/Qwen3.6-27B
--served-model-name Qwen3.6-27B
--host 0.0.0.0
--port 8000
--max-model-len 262144
--tensor-parallel-size 2
--gpu-memory-utilization 0.85
--max-num-seqs 8
--enable-prefix-caching
--enable-chunked-prefill
--trust-remote-code
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--performance-mode throughput
--language-model-only
--kv-cache-dtype auto
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":4}'
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "3"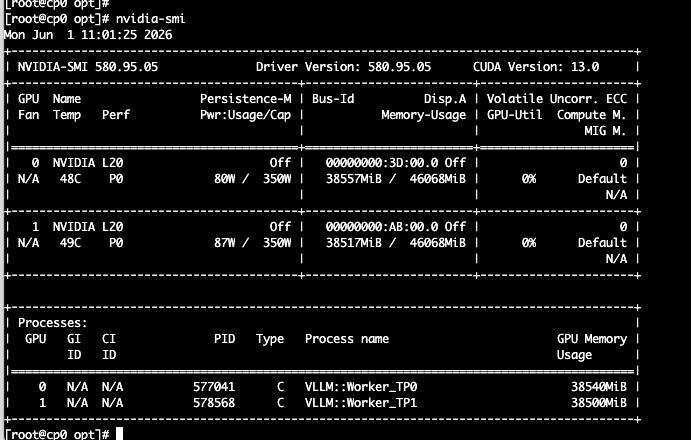
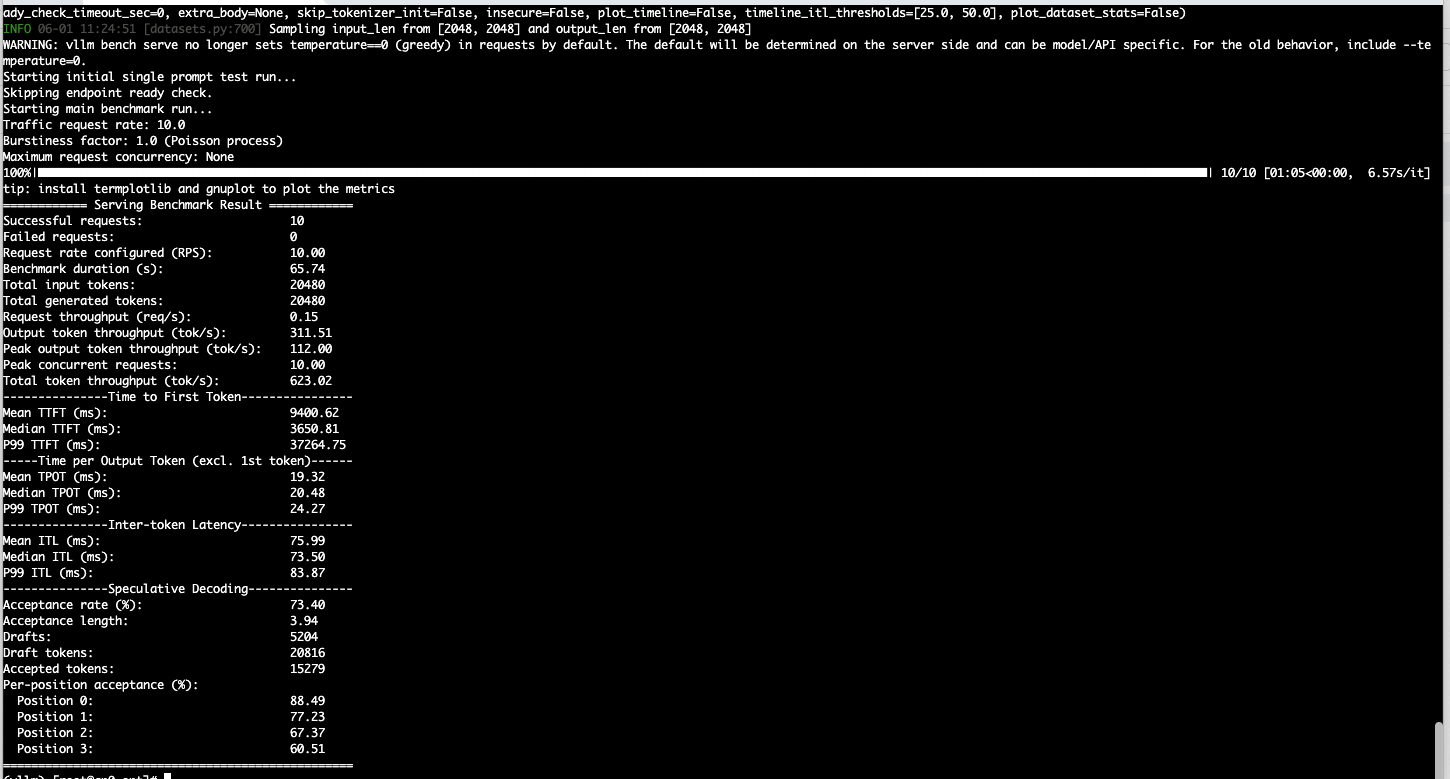
单并发测试结果:
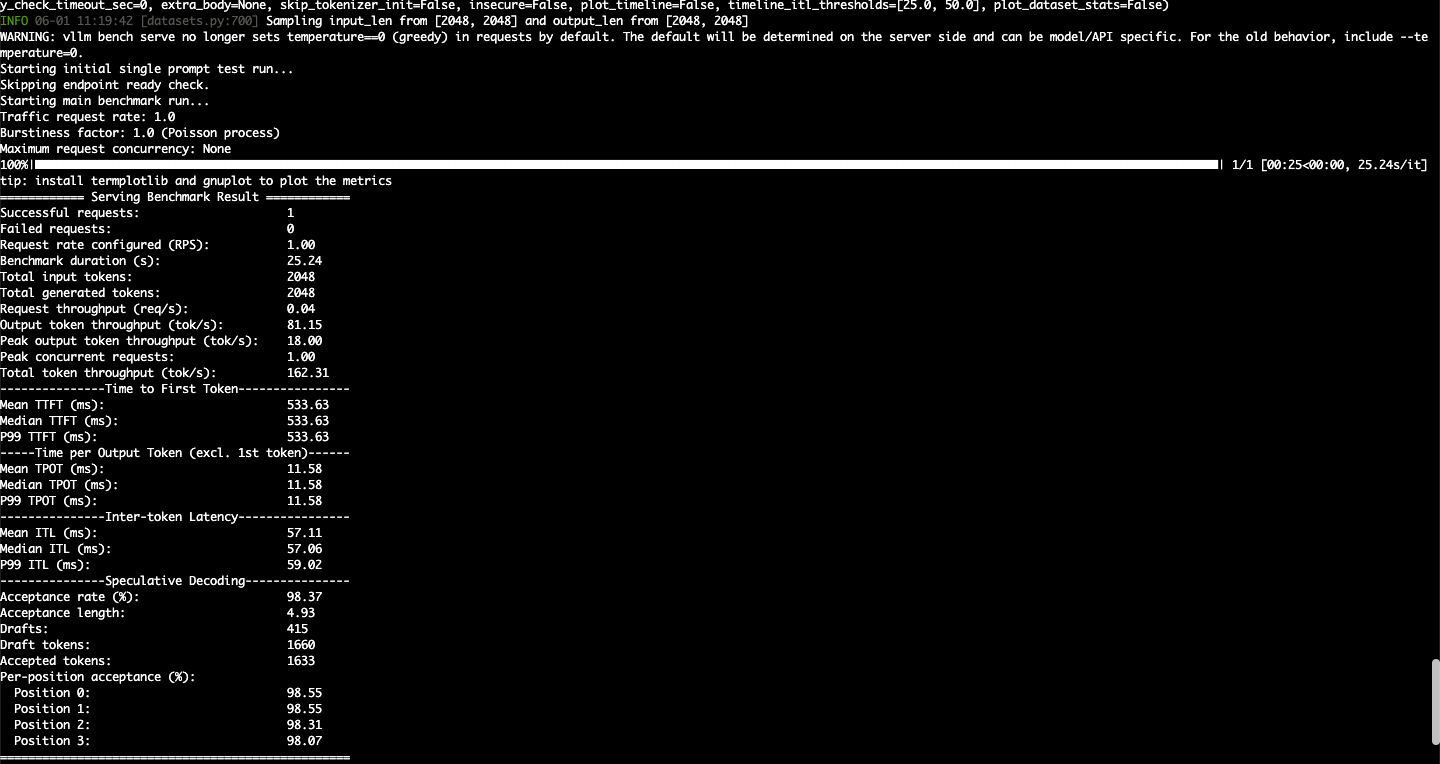
总耗时:25.24s
输入:2048 tokens
输出:2048 tokens
总 token 数: 4096 tokens
输出吞吐:81.15 tokens/s
总token 吞吐:162.31 tokens/s
第一个生成 token:533.63 ms
每个输出 token 平均耗时:11.58 ms --> 换算为token/s:1000/11.58 == 86.35 tokens/s
token 间延迟平均值:57.06ms
10并发测试结果