LoRa模型微调实战
使用 LLama-Factory 进行模型微调
安装 LLama-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple
conda activate vllm
#查看版本号
llamafactory-cli version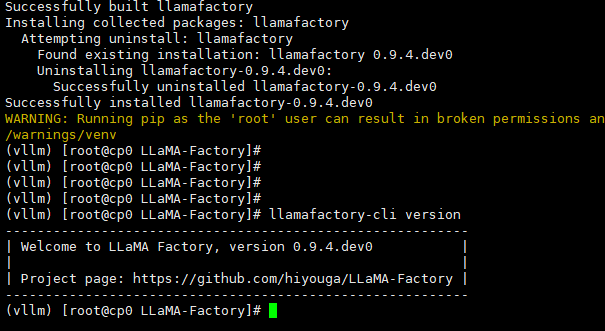
启动 LLama-Factory
注:llamafactory-cli webui 这个启动命令,如果不在拉去的代码目录下启动的话他是识别不了data的相对路径的如图:
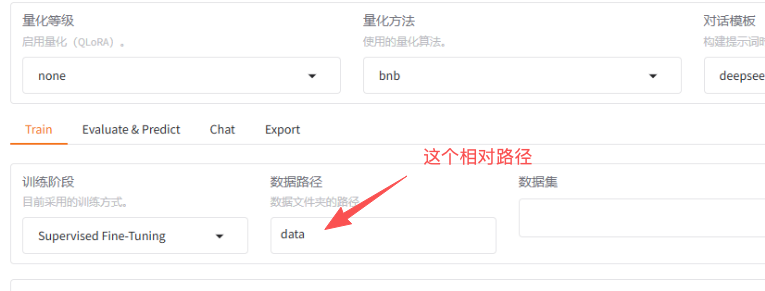
如果在项目外启动,数据文件夹路径需要写绝对路径。
#创建一个启动脚本,进行后台启动llamafactory的webui
vim run_llama-factory.sh
#内容只有一行命令
nohup llamafactory-cli webui > /data/LLaMA-Factory/llamafactory.log 2>&1 &
chmod +x run_llama-factory.sh
bash run_llama-factory.sh
模型下载
mkdir /data/Qwen3-4B-Instruct-2507
modelscope download --model Qwen/Qwen3-4B-Instruct-2507 --local_dir /data/Qwen3-4B-Instruct-2507
modelscope download --model AI-ModelScope/m3e-base --local_dir /data/m3e-base页面介绍
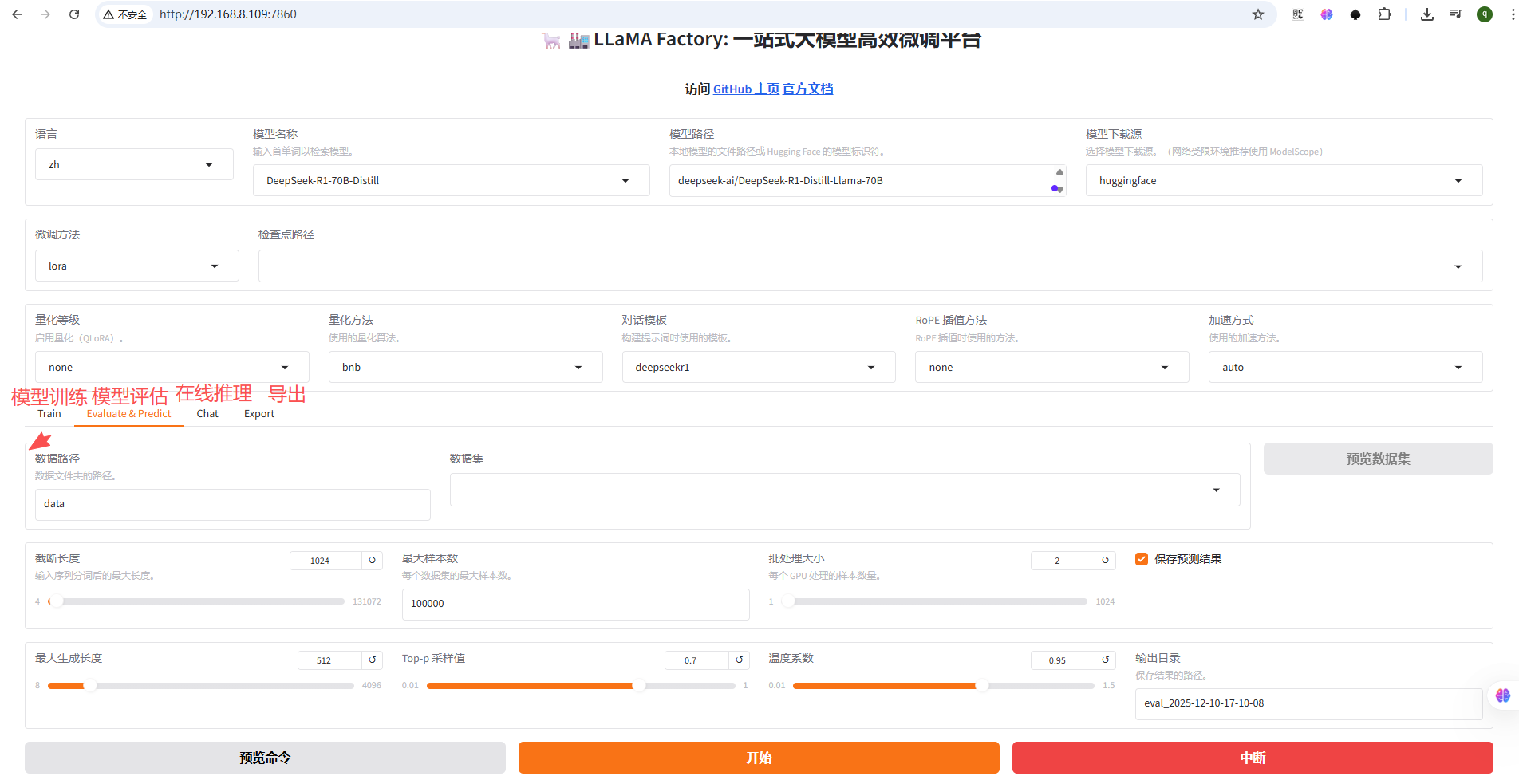
模型训练页面
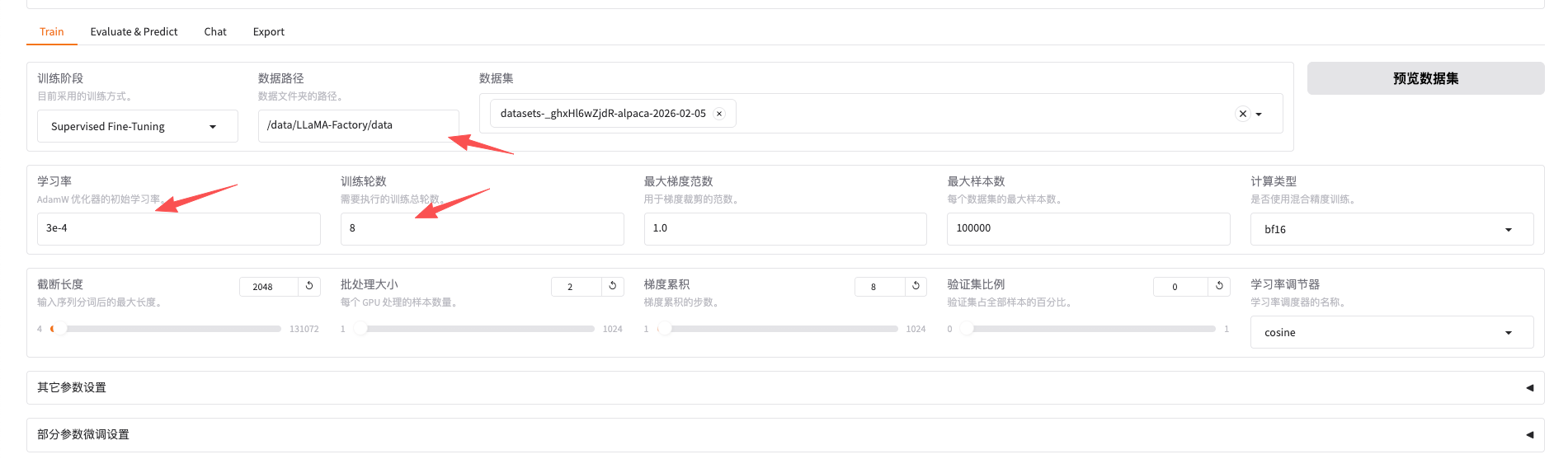
学习率:默认为5e-5(5 × 10⁻⁵,即0.00005) 是全参数微调的推荐设置,但是不一定适用,根据不同的业务场景它的学习率是不一样的,学习率可以理解为“参数调整的大小,比如设置为3e-4,这个值比5e-5要大,这它在微调的时候修改的参数就越多”。
训练轮次:表示同一个数据集训练几轮。
注:目前还在学习阶段,所调整的参数仅限这两个参数。
第一次实战:
我通过设置这两个参数进行一个模型的微调
用Easy Dataset 来进行数据集的生成。
【maxkb.md】https://www.kdocs.cn/l/coy08ajglkLa
注:maxkb.md是网页文档给他拔下来的md格式文档。
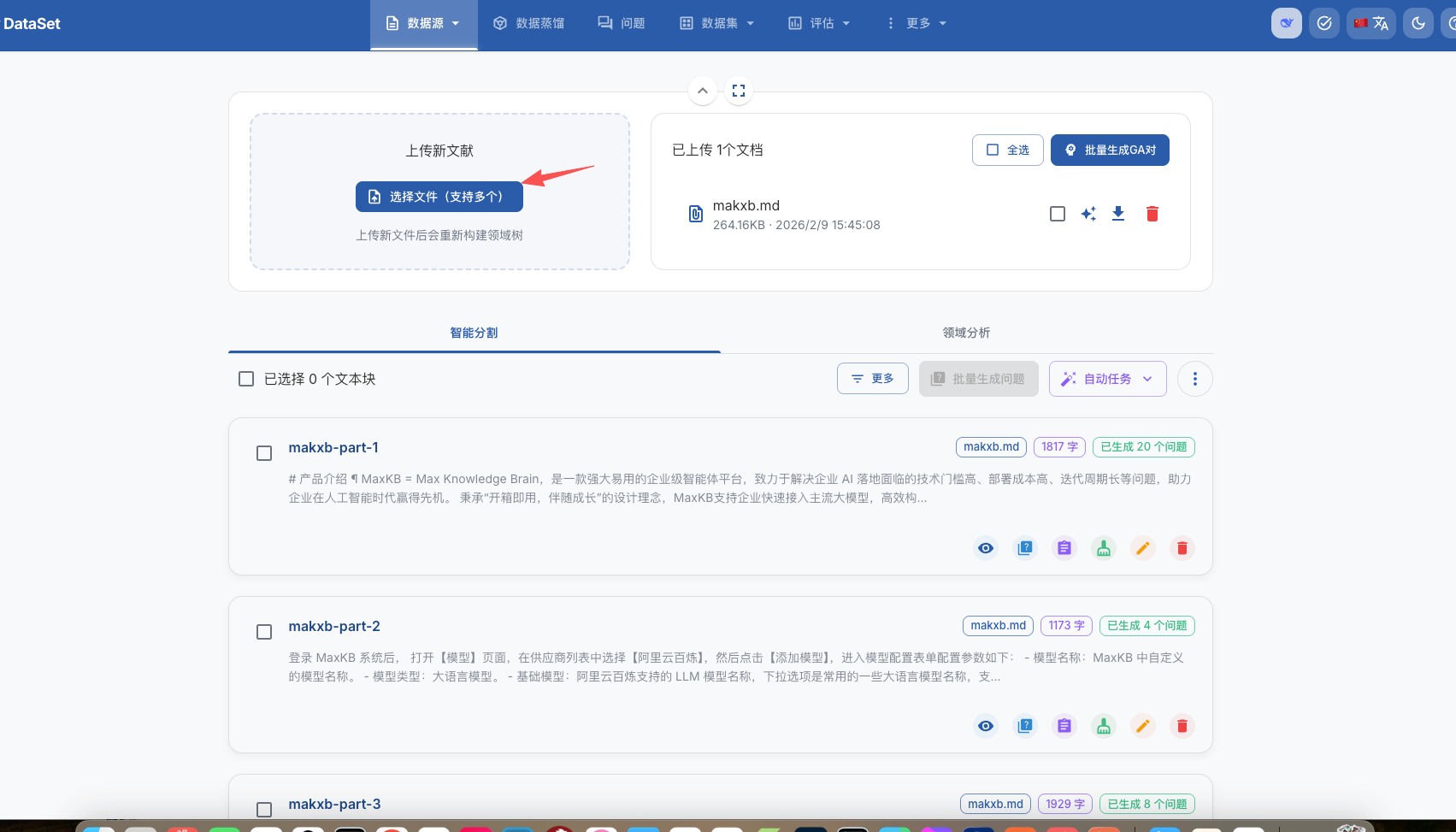
上传完文档他会进行智能分块,这里的智能分块感觉是根据markdown的一级标题、二级标题进行切分的。
切分完之后可以进行数据蒸馏,也可以对每个分块进行生成对应的问题
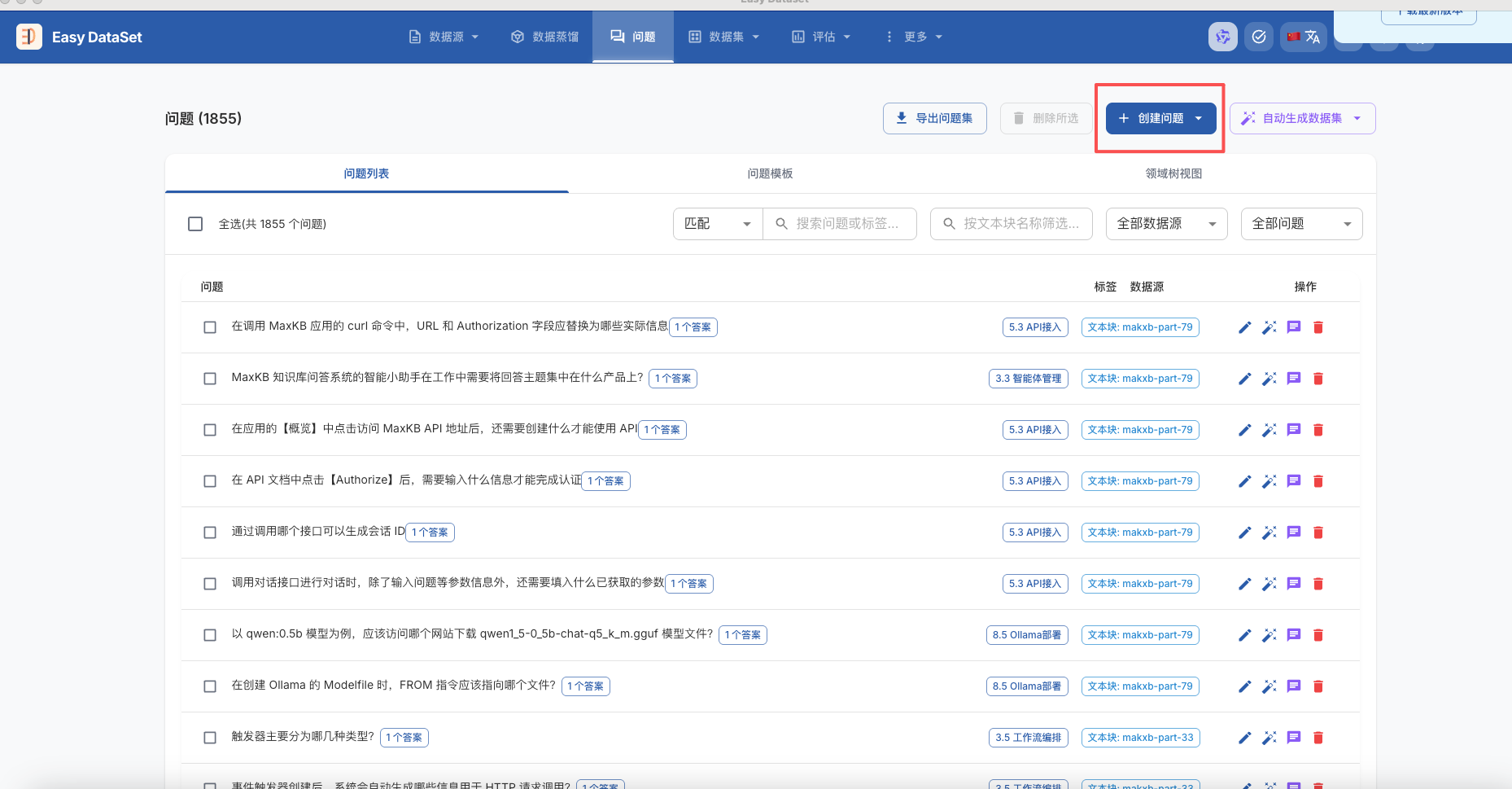
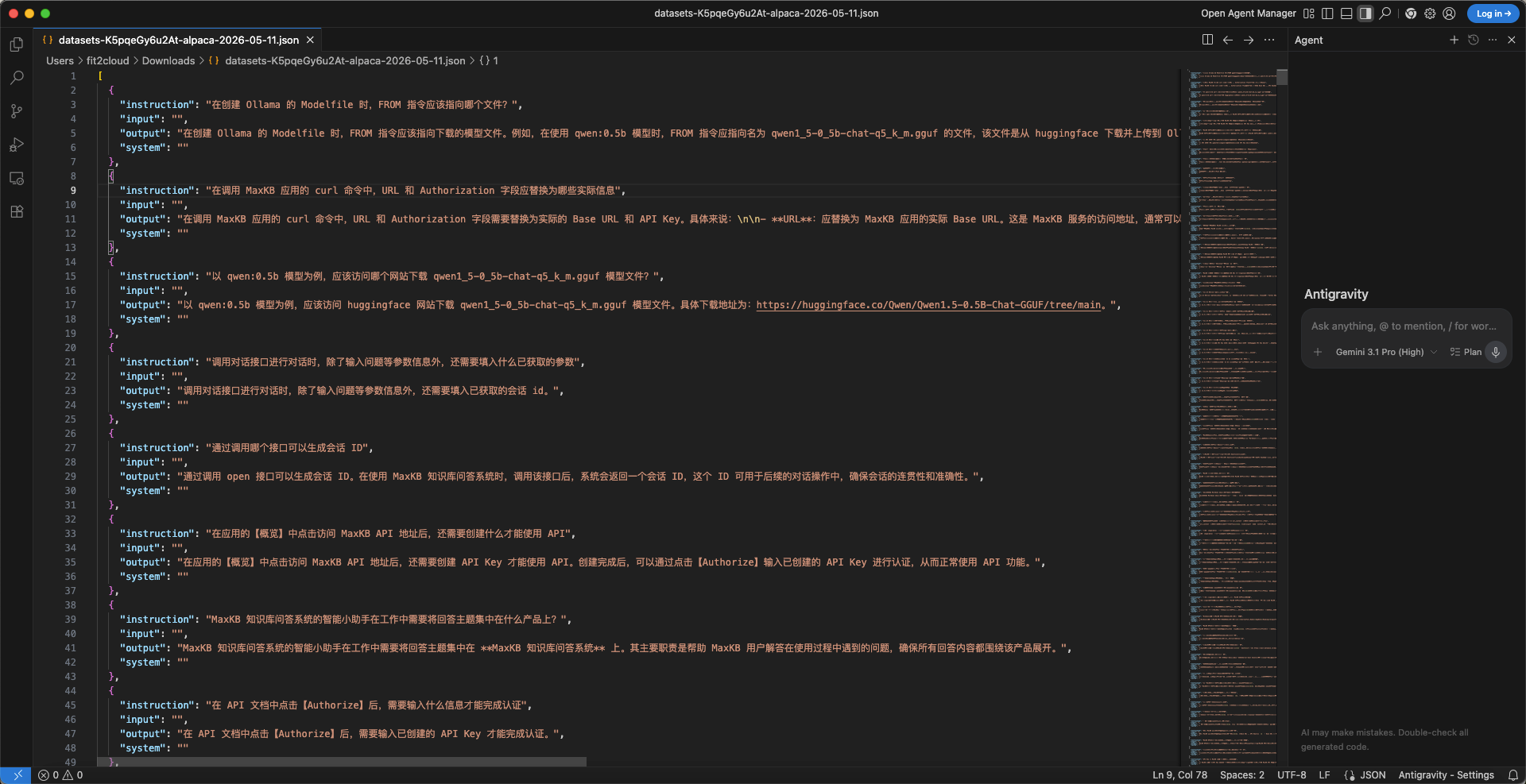
到数据集中导出相应的格式的数据集,为json格式的数据。
格式如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)"
}
]