MaxKB 处理图片类型PDF进行知识库入库
背景
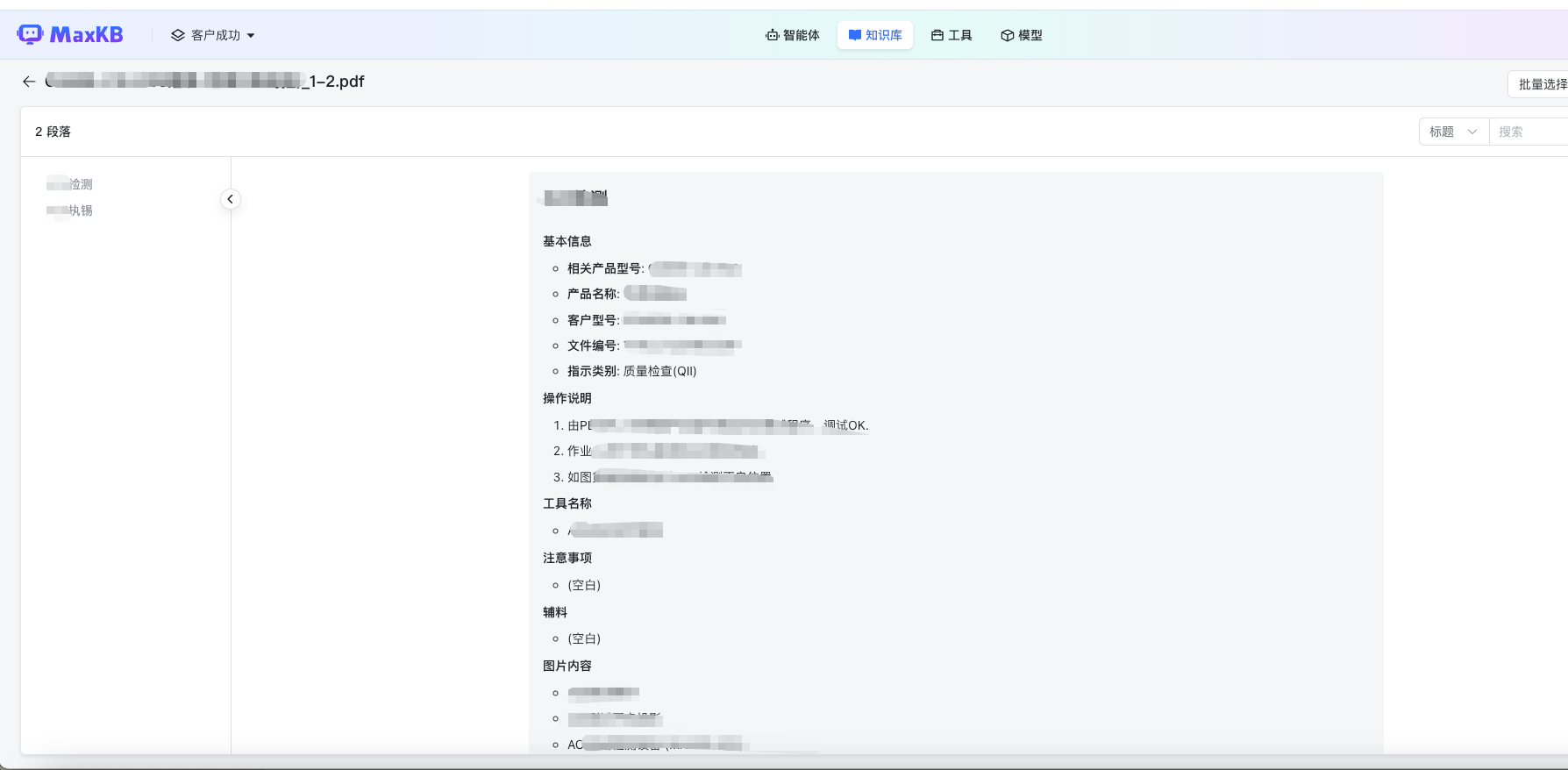
有些工厂,他们的企业知识文档不是常规的文本格式文档,而且类似图片+表格的形式进行展示的,如下:

这种有表格有图片的pdf,如果直接上传到MaxKB 中识别成文字内容是错乱的,一个大的分段内容会被截取,具体如下:
实现
这样的知识库是没有任何使用价值的,我们需要使用工作流通过后期的工具去处理这种特殊场景的文档。
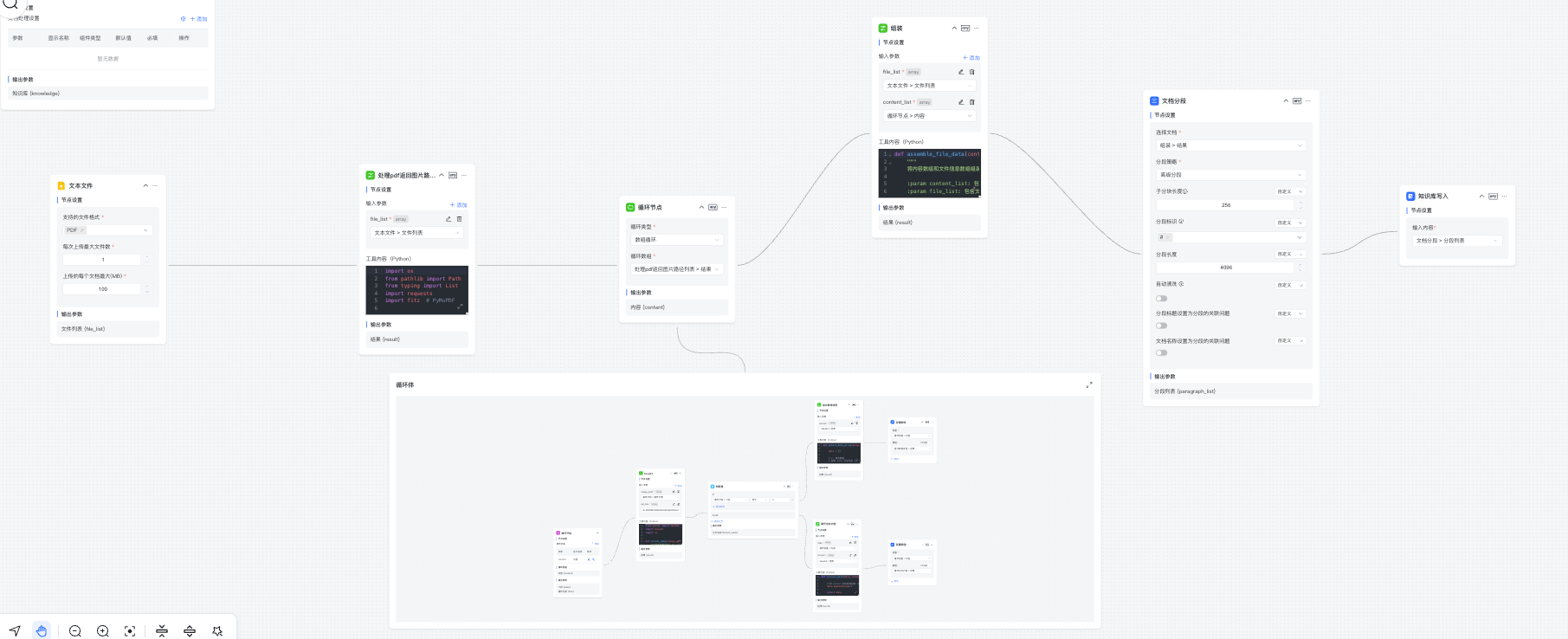
我这里的思路是先将PDF的文档通过代码写一个转化工具将每一页的PDF转化成一张张图片,存放在一个图片数组中,然后使用循环节点通过本地的图片理解模型去将图片的内容解析出来,生成markdown格式的内容,然后在调用MaxKB 的API 进行入库。
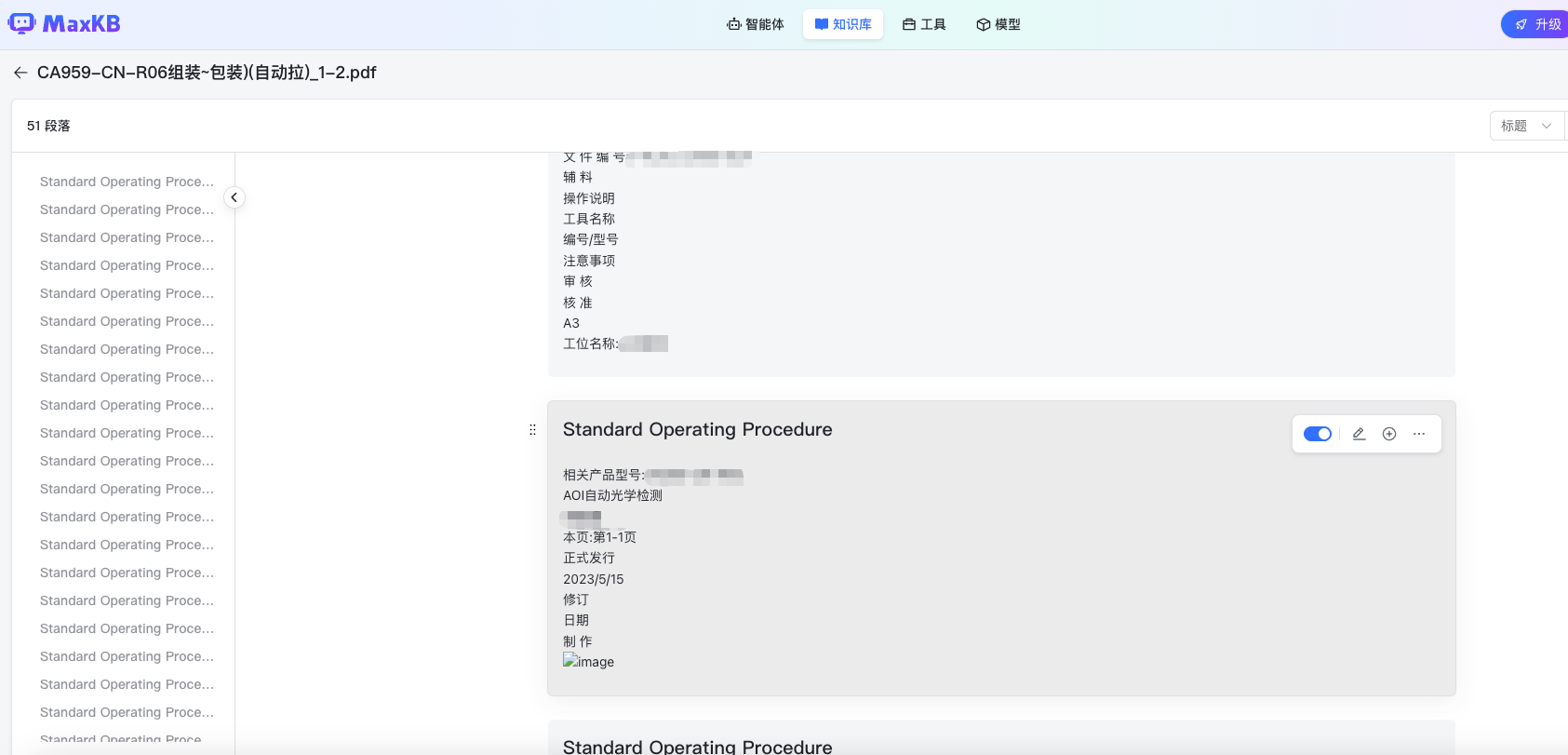
效果
处理出来结果是每一个分段为一个指导书的内容,内容包括基本信息,操作说明,工具名称等主要信息如下: